从 Volta 到 Rubin:NVIDIA 数据中心 GPU 如何重塑 AI 基础设施
从 Tensor Core、HBM 和 NVLink,到机柜级 AI Factory:GPU 的代际升级,表面是算力与显存升级,本质是对 AI 工作负载、集群通信和数据中心运营成本的持续重构。
如果让你为一家 AI 公司采购 1,000 张 GPU,你真正要买的是什么?
答案不是 1,000 块插进服务器就能工作的加速卡,而是一套彼此咬合的系统:服务器要装得下,网络要跑得满,存储要供得上,供电要扛得住,冷却要压得住热量,软件平台还要让训练任务稳定地跨越数百乃至数千块 GPU。
少了其中任何一环,昂贵的 GPU 都可能变成机房里“最贵的等待队列”。
这正是理解 NVIDIA 数据中心 GPU 演进的关键。大模型的瓶颈早已不只是芯片能做多少次浮点运算,还包括模型是否装得下、数据是否送得进、GPU 之间是否跟得上,以及每生成一个 Token 究竟要花多少钱。NVIDIA 的竞争对象也不只是 AMD 等芯片厂商,还包括云厂商的自研加速器、各种专用 AI 芯片,以及客户有限的基础设施预算。
从 Volta 到 Rubin,NVIDIA 的产品重心因此不断上移:
从一张更快的卡,到一台更强的服务器,再到一个能够持续生产 Token 的机柜和 AI Factory。
这篇文章不会把 GPU 写成一串令人眼花缭乱的 FLOPS 参数,而是回答一个更重要的问题:为什么它们必须这样演进?
一、先建立共同语言:看懂 GPU 的五个关键维度
比较 GPU,最容易掉进“峰值算力越高,实际性能越好”的陷阱。真实 AI 系统的速度,通常由计算、显存、通信、软件和数据中心运营五个维度共同决定。
1. 计算:Tensor Core 为什么是分水岭
CUDA Core 是通用并行计算单元,适合向量、标量和控制逻辑等多类运算;Tensor Core 则专门加速矩阵乘加。Transformer 中的注意力与前馈网络,本质上包含大量矩阵乘法,因此 Tensor Core 与现代 AI 工作负载天然契合。
…工程化记忆:大模型短期记忆与长期记忆的驾驭之道
记忆不是存储问题,而是时机问题。
引言:AI 的"金鱼困境"
你把一个需求拆成五步告诉 AI。第一步它理解得很好,第二步它开始调用工具,第三步它停下来问你要一个——已经在第一轮对话里告诉过它的信息。
这不是模型不够聪明。GPT-4o、Claude 4.6、Gemini 3.1 Pro,任何一个前沿模型在单轮推理能力上都已经足够出色。问题是:它们记不住。或者说,它们记不住"该记住的东西"。
这个困境有一个形象的类比——金鱼困境。金鱼的记忆只有七秒,而大模型的"记忆"取决于上下文窗口能塞进多少 Token。但 Token 有成本,窗口有上限,信息会稀释。即便上下文窗口从 4K 扩展到 128K 再到 1M Token,“记住"这件事远没有变得简单。
为什么?因为记忆不是存储问题,而是时机问题。
一个 AI 系统需要知道:
- 什么时候该把信息写进记忆?
- 该写什么?该忘什么?
- 什么时候该从记忆中召回信息?
- 召回后怎么注入当前对话而不破坏上下文?
这些问题没有标准答案。不同场景有不同的选择,不同选择构成不同的架构。本文的目标是把这个决策空间清晰地画出来,让你在设计自己的 AI 系统时,能像工程师一样思考"记忆"这件事。
一、记忆系统的分层架构
1.1 双存储模型的工程启示
在认知科学中,有一个经典的双存储模型(Dual-Store Model):信息先进入短期记忆(工作台),经过编码和巩固后转入长期记忆(仓库)。工程化 AI 记忆的架构,几乎就是对这个模型的直接映射。
把这张图画出来可能更直观:
┌──────────────────────┐
│ 外部输入 │
└──────────┬───────────┘
▼
┌─────────────────────────────────────────────────┐
│ 短期记忆(上下文窗 │
│ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │ System │ │ Message │ │ Agent State │ │
│ │ Prompt │ │ History │ │ (Tool Calls) │ │
│ └──────────┘ └──────────┘ └──────────────┘ │
└──────────────────────┬──────────────────────────┘
│ 写入编码(Write)
▼
┌─────────────────────────────────────────────────┐
│ 长期记忆(跨会话存储) │
│ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │ 向量记忆 │ │ 结构化记忆 │ │ 图记忆 / 关系 │ │
│ │ (RAG) │ │ │ │(Graph Memory)│ │
│ └──────────┘ └──────────┘ └──────────────┘ │
│ ↑ 召回检索(Read) │
└─────────────────────────────────────────────────┘
1.2 短期记忆(STM):上下文窗口内的"工作台”
短期记忆是 AI 当前正在"思考"的内容。在技术层面,它就是 LLM 的上下文窗口(Context Window)——输入给模型的所有 token 总和。
…RabbitMQ 深度实践:在 Kubernetes 上构建生产级消息队列
服务已经全面上了 Kubernetes,但消息队列还孤零零地跑在一台虚机上——这是很多团队在云原生迁移中都会遇到的阶段性尴尬。消息队列的 K8s 化比无状态服务复杂得多:数据持久化、集群选主、滚动升级期间的消息可靠性,每一项都需要在部署前想清楚。
本文面向已在 K8s 上运维过服务、正在考虑引入或迁移消息队列的工程师。内容沿"选型 → 核心概念 → 生产部署 → 高可用 → 可观测性 → 业务落地 → 故障排查"这条工程路径展开,读完后你能独立完成 RabbitMQ 在 K8s 上的全链路落地。
一、先做选型:RabbitMQ、Kafka、RocketMQ 如何抉择
在深入 RabbitMQ 之前,先用 3 个问题确认它是否适合你的场景——如果答案都是"否",后续内容可能不适合你现在的需求。
决策树:
Q1. 你的消息需要"消费后保留并支持历史回放"吗?
├── 是 → 考虑 Kafka(事件日志语义)
└── 否 → 继续 Q2
Q2. 单队列 TPS 是否超过 10 万/s?
├── 是 → 考虑 Kafka 或 RocketMQ(吞吐优先场景)
└── 否 → 继续 Q3
Q3. 是否需要分布式事务消息或精确到秒的延迟消息?
├── 是 → 考虑 RocketMQ(电商事务场景原生支持)
└── 否 → RabbitMQ 是你的首选
如果你走到了最后一个"否",那么 RabbitMQ 的低延迟(<1ms)、灵活路由(多种 Exchange 类型)和成熟的 K8s Operator 是难以替代的优势。
…GPU 芯片全景:国内外厂商对比、市场格局与异构部署实践
随着大模型训练与推理需求的爆发,GPU 芯片从图形处理器演变为 AI 时代最核心的算力基础设施。本文系统梳理国内外主要 GPU 厂商的芯片系列、性能横向对比、市场格局,以及软件生态与异构混合部署的架构实践,供技术选型参考。
1. 为什么 GPU 在 AI 时代如此关键
1.1 从图形渲染到通用并行计算
GPU(Graphics Processing Unit)最初的设计目标是加速图形渲染,其核心特点是大量小型计算核心(相对 CPU 的少量大核)并行执行相同指令。这一特性与深度学习中大规模矩阵乘法的计算模式高度契合。
CPU 的设计哲学是降低单任务延迟:深流水线、乱序执行、大缓存,少量强力核心串行处理复杂逻辑。GPU 则以吞吐量为核心:数千个简单核心同时执行相同操作,用于处理矩阵乘、卷积等高度并行的数学运算。
2006 年 NVIDIA 发布 CUDA(Compute Unified Device Architecture),首次将 GPU 开放给通用计算场景,标志着 GPGPU(General-Purpose GPU)时代的开始。2012 年 AlexNet 在 ImageNet 竞赛中取得突破性成绩,其背后的关键之一就是 GPU 加速训练——GPU 正式进入 AI 主流视野。
1.2 大模型训练与推理的算力需求
大模型的算力需求可从以下几组数据量化:
- GPT-3(1750 亿参数)训练消耗约 3640 PFlop/s-day,相当于 1024 块 A100 运行约 34 天
- Llama 3 405B 的训练使用了超过 16000 块 H100
- 一次 GPT-4 的推理请求,需要多张 GPU 协同完成
训练与推理对 GPU 的需求有所不同:
…Harness Engineering:当模型趋同,胜负在模型之外
同一匹马,套上不同的挽具,有的能拉着马车一路狂奔,有的却原地打转。
今天的大模型也是如此。模型只是那匹马,决定它能干多少活的,是套在它身上的那套"挽具"——Harness。
引言:为什么同一个模型,能力却天差地别?
关注 AI Coding Agent 的人,大概都撞见过一个反常的现象。
在 SWE-bench(一个用真实 GitHub issue 考验 AI 修 bug 能力的基准)榜单上,同一个底层模型被不同工具调用,分数能差出二三十个百分点:同样的 Claude 或 GPT,套在 SWE-agent 上是一个成绩,套在 Aider、OpenHands、Claude Code 上又是另一个成绩。模型没变,权重一个比特都没动,能力却像换了一个档次。
你自己多半也体验过:同一个模型,在 A 工具里像个磕磕绊绊的实习生,换到 B 工具里突然又快又准。换的不是马,是马身上那套家伙什。
差距来自模型外面那一层——它怎么读代码、怎么调工具、怎么管理上下文、出错了怎么回退、什么时候该停。这套包裹在模型外围的工程系统,就是本文的主角:Harness(智能体外壳 / 挽具);围绕它的设计与实践,正被越来越多人称为 Harness Engineering。
随着模型越来越强、越来越同质化,一个判断正成为共识:
模型决定能力的上限,Harness 决定你能榨出多少。
第一部分:harness 一词从哪来——从"测试外壳"到"智能体外壳"
1.1 老程序员都熟悉的 “Test Harness”
“Harness” 在软件工程里并不新鲜。写过自动化测试的人,都听过 Test Harness(测试外壳 / 测试夹具):为了让"被测系统"能自动跑起来,在它外围搭的那一整套支撑设施——喂入输入、驱动执行、捕获输出、比对结果。被测代码是核心,但没有这层外壳,它既跑不起来,也无法被反复、稳定地验证。
harness 的英文本义是马具、挽具——套在马身上、把马力传导到马车上的那套皮带和装置。这个隐喻非常精准:
- 被测系统 / 模型 = 马(提供原始动力)
- harness = 挽具(约束、引导、把动力传导到正确的方向)
马再有劲,没有挽具也只是一匹野马;套上挽具,它才能拉着车往你要去的地方走。
1.2 大模型时代,“外壳"重新变得关键
当 LLM 从"对话补全"走向"自主完成任务”,一个老问题换上新形式回归:一个只会预测下一个 token 的模型,没法直接干活。它需要被放进一个循环里——
- 感知:读取当前任务和环境状态
- 思考:决定下一步做什么
- 行动:调用工具(读文件、跑命令、搜索……)
- 观察:拿到工具返回的结果
- 回到第 1 步,直到任务完成或失败
这个"感知—思考—行动—观察"的循环,加上支撑它运转的所有代码——工具定义、上下文拼装、提示词模板、错误处理、停止判断、权限控制——合在一起,就是 Agent Harness(智能体外壳)。
…从单机到千卡集群:Ray 如何让 Python 代码拥有超能力?
引言:一个让 Python 程序员"无痛"进入分布式计算的框架
为什么训练 AI 模型越来越像"喂显卡吃数据"?
2023 年,GPT-4 的参数规模达到了 1.8 万亿。这个数字意味着什么?如果把它想象成一座图书馆,那大约是 1800 亿本书——而这些"书"需要在成百上千张 GPU 上同时被"阅读"和"理解"。
训练这样的模型,单张显卡已经远远不够。你需要分布式计算:把任务拆分到多台机器、多张显卡上并行执行。但传统的分布式编程方式,对大多数 Python 开发者来说,简直是一场噩梦。
Ray 是什么?
Ray 是一个让 Python 代码自动具备分布式能力的开源框架。
它的核心魔法极其简单:给你的 Python 函数加上 @ray.remote 装饰器,这个函数就能在集群中的任意节点上并行执行。从单机笔记本到千卡集群,同一套代码,无需重写。
这不是魔法,这是来自 UC Berkeley RISELab 的工程师们,为 AI 时代的 Python 开发者精心设计的分布式抽象。
为什么 OpenAI、Uber、Shopify 都选择了它?
- OpenAI:用 Ray 训练 ChatGPT,从 MPI 迁移过来后,基础设施复杂度降低了十倍以上
- Uber:基于 Ray 构建实时供需预测系统,每天处理数百万订单
- Shopify:基于 Ray 搭建 ML 平台 Merlin,实现从 Jupyter 到生产的无缝衔接
这些公司的共同点是什么?他们都在解决同一个问题:如何让 AI 研发和部署变得更简单、更快速、更便宜。
这篇文章,我们就来聊聊 Ray 到底是什么,它解决了 AI 工程的哪些痛点,以及为什么它正在成为分布式 AI 计算的工业标准。
第一部分:Ray 是什么——给 Python 的分布式超能力
1. Ray 诞生的故事:UC Berkeley 的学术项目如何变成工业标准
从 RISELab 走出
2016 年,加州大学伯克利分校的 RISELab(Real-Time Intelligent Systems and Engineering Laboratory)诞生了一个新项目。这个实验室的前身是著名的 AMPLab,也就是 Spark 和 Mesos 的发源地。
…Coding Agent 崛起之后:软件研发哪些变了,哪些永远不会变?
“你今天写了多少行代码?”
这个曾经衡量程序员生产力的问题,正在变得越来越没有意义。
引言:那个"敲代码"的时代,正在结束
2023 年之前,软件工程师的核心工作可以被粗暴地概括为一件事:把人类的意图翻译成机器能理解的语言。这个翻译过程极度耗费精力,门槛极高,也正因如此,“会写代码"在过去二十年里是一张含金量极高的入场券。
然而现在,翻译机器出现了。
从 GitHub Copilot 到 Cursor,从 Claude Code 到 OpenHands,AI 对软件开发的介入已经不再停留在"补全一行代码"的层面——它开始接管完整的任务执行:理解目标、拆解步骤、调用工具、修改文件、执行测试、自主迭代。
一个越来越难以回避的问题摆在每一个工程师面前:
如果 AI 已经会写代码了,我们真正的价值是什么?
本文无意制造焦虑,也不打算用廉价的乐观主义宽慰任何人。我们想做的,是认真审视 Coding Agent 的崛起究竟改变了哪些研发流程,哪些工程能力会被削弱,哪些能力反而会在这个新时代里被放大——以及那些软件工程最核心的本质,为什么 AI 永远无法替代。
第一部分:从"代码生产"到"意图生产”——软件开发范式的根本转变
1.1 过去的软件研发,本质是"人肉编译业务逻辑"
在 AI 介入之前,一个完整的软件研发循环大致如此:产品经理写需求文档,开发工程师理解需求,将其拆解为可执行的技术任务,手工编写代码,本地调试,联调接口,提交测试,再经过若干轮迭代最终部署上线。
这个过程的核心瓶颈始终只有一个:从"想法"到"实现"的转换成本极高。
不是因为工程师不够聪明,而是因为编程语言本身就是一道高门槛的翻译屏障。想要让计算机理解"用户点击按钮后应该弹出一个确认框",你需要掌握某种编程语言的语法,理解事件驱动模型,知道如何操作 DOM 或调用对应的 UI 框架 API——这些都是纯粹的"翻译成本",和业务逻辑本身没有任何关系。
正是这道翻译屏障,让"会写代码"长期拥有极高的市场溢价。
1.2 AI 出现后,最大的变化不是"生成代码",而是"压缩翻译成本"
很多人对 AI Coding 工具的理解还停留在"它能帮我写代码"这个层面。但这个理解是不完整的。
Coding Agent 真正改变的,是整条价值链的权重分布。
以 Claude Code 或 OpenHands 这类具备任务执行能力的 Agent 为例,它们的工作方式是:接收人类定义的目标,自动规划执行步骤,调用文件系统、终端、浏览器等工具,修改代码并运行测试,根据结果自主调整策略。整个过程中,人类的主要工作从"实现者"变成了"指挥者"。
这意味着 AI 开始系统性地接管以下工作:
- 重复性编码:样板代码、CRUD 接口、数据格式转换
- 胶水代码(Glue Code):API 集成、第三方 SDK 接入
- 测试生成:单元测试、Mock 数据、回归用例
- 文档生成:函数注释、README、接口说明
这些工作不是不重要,而是它们对人类认知能力的要求相对较低,却消耗了工程师大量的时间和精力。AI 将这部分时间解放出来,理论上让工程师可以把精力集中在更高阶的问题上。
…企业级 RAG 实战指南:从理论到落地的完整避坑手册
本文系统梳理了 RAG(检索增强生成)技术在企业场景中的落地全流程,涵盖五大应用场景、六步实施路径,以及十大常见陷阱的针对性解决方案。无论你是刚接触 RAG 的初学者,还是正在部署企业知识库的工程师,都能从中获得可落地的实践经验。
一、为什么企业需要 RAG?
1.1 LLM 的先天局限
你们公司有多少份内部文档?产品手册、IT 规范、人事制度、历史工单、会议纪要……保守估计几千份,多的几十万份。这些文档里藏着公司真正的运营知识,但员工每天花大量时间在"找东西"上,而不是"用东西"上。 直接用 ChatGPT 或者任何通用大模型,有三个无法绕过的硬伤:
- 知识实效性: 模型训练有时间窗口,你公司上个月刚更新的报销政策,它永远不知道。
- 领域盲区: 它对你的业务一无所知,给出的答案泛泛而谈,对你的具体场景没有参考价值。
- 幻觉: 它会在不知道的时候"编"一个看起来很正确的答案,而你的员工可能直接照着执行了。
1.2 RAG 的破局之道
RAG(Retrieval-Augmented Generation,检索增强生成)解决的正是这三个问题。它通过"检索 + 生成"的架构,让 LLM 能够基于企业私有知识回答问题:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 用户提问 │ ──→ │ 检索知识库 │ ──→ │ LLM 生成 │
│ (Question) │ │ (Retrieve) │ │ (Generate) │
└─────────────┘ └─────────────┘ └─────────────┘
↑
┌─────────────┐
│ 企业私有数据 │
│ 产品文档/制度 │
│ 客服记录/论文 │
└─────────────┘
核心优势:
- 知识实时更新:新文档上传即可被检索
- 领域精准回答:基于企业专属知识生成
- 答案可溯源:每个回答都能定位到原文出处
- 成本可控:无需微调 LLM,性价比极高
二、企业 RAG 的五大黄金场景
场景 1:智能客服问答
痛点: 客服人员需要记忆大量产品知识,重复问题消耗人力
…当 AI 能写代码,我们还需要软件工程师吗?
“软件正在吞噬世界。” — Marc Andreessen,2011 年
而今天,AI 正在吞噬软件的执行层。那些曾经定义我们职业身份的事情,正在被一个工具接管。
一个让人不安的早晨
你盯着那段代码,脑子里冒出一个问题:这件事,还需要我吗?
你打开 LinkedIn,又看到几条熟悉的消息:某大厂裁员,某初创公司宣布用 AI Agent 替代了整个外包团队、Anthropic CEO Dario Amodei 的预言——未来 AI 将取代 50% 的初级岗位。你关掉页面,打开 IDE,却发现 Copilot 已经把你想写的函数补全了——连注释都写好了。
你盯着那段代码,心里升起一个问题:我还有存在的必要吗?
这个问题,正在折磨全球数百万软件工程师。它值得被认真对待,而不是被一句"别担心,AI 只是工具"草草打发。
但在焦虑淹没你之前,我们需要先搞清楚:这个问题本身,是不是问错了?
一、恐慌背后的真实数据
让我们先直视那些令人不安的数字。
根据斯坦福数字经济研究所 2025 年的报告,AI 曝光度最高的岗位——IT 和软件工程——22 至 25 岁群体的就业率从 2022 年峰值下滑了约 20%。与此同时,35 至 49 岁的工程师群体就业率却上涨了 9%。年轻人进不来,经验者更吃香。
Stack Overflow 2025 年开发者调查显示,84% 的开发者现在已经在日常工作中使用 AI 辅助工具,而这一比例在 2023 年还只有 70%。AI 工具的渗透速度之快,超过了大多数人的预期。
初级工程师的传统入场路径——实习——也在急速萎缩。招聘平台 Handshake 的数据显示,科技类实习职位自 2023 年以来缩减了 30%,而申请人数却增加了 7%。哈佛大学针对 6200 万名劳动者的研究同样发现,企业采用生成式 AI 之后,初级开发者的雇用在六个季度内下降了约 9% 至 10%,而资深开发者几乎不受影响。
…Claude Code 是如何工作的?一个自主编程智能体的架构深度解析
你有没有想过,当你在终端输入
claude "帮我重构这个认证模块"之后,接下来的几分钟里究竟发生了什么?Claude 是怎么在没有任何人逐步指导的情况下,自己找到文件、理解代码结构、做出修改、运行测试、再迭代修复的?这篇文章试图从架构层面,把这个过程讲清楚,面向对 AI 智能体设计有兴趣的工程师和产品人。如果你只是想用好 Claude Code,这篇文章同样能帮你建立一个清晰的心智模型,让你知道什么样的任务适合它,什么样的指令能让它发挥最大效果。
一、从聊天机器人到自主智能体:一次真正的范式跃迁
要理解 Claude Code 的架构,我们需要先理解它身处的历史节点。
2023 年之前,AI 应用基本上只有一种形态:你问,它答。ChatGPT 的出现让对话式 AI 飞入寻常百姓家,但本质上它是无状态的——每一轮对话都是独立的,AI 没有目标,没有计划,更没有行动能力。它像一个极其博学的图书管理员,你问什么,它查什么,查完就完了。
随后涌现出大量工作流编排工具,n8n、LangChain、Dify……这类工具的思路是:由工程师预先定义好 AI 应该执行的步骤——先调用这个 API,再走这个判断分支,然后输出到那里。模型被嵌入到一个硬编码的 DAG(有向无环图)里,充当某个节点上的智能处理单元。这是进步,但代价是严重的刚性:流程一旦设计好,AI 就被锁死在既定的轨道上,遇到意外情况毫无应对能力。
Claude Code 代表的是第三个阶段。在这里,控制权发生了根本性的翻转:不再是代码控制模型,而是模型控制代码。运行时框架变成了一个极度精简的"容器",所有的推理、规划、决策,全部交给 Claude 模型自己完成。它不只是在回答问题,而是在追求目标——理解你想要什么,制定策略,执行行动,观察结果,修正方向,直到任务完成。
这个转变听起来像是细节,实际上是量变引发质变的那个临界点。
二、核心架构:一个大脑,一副躯体
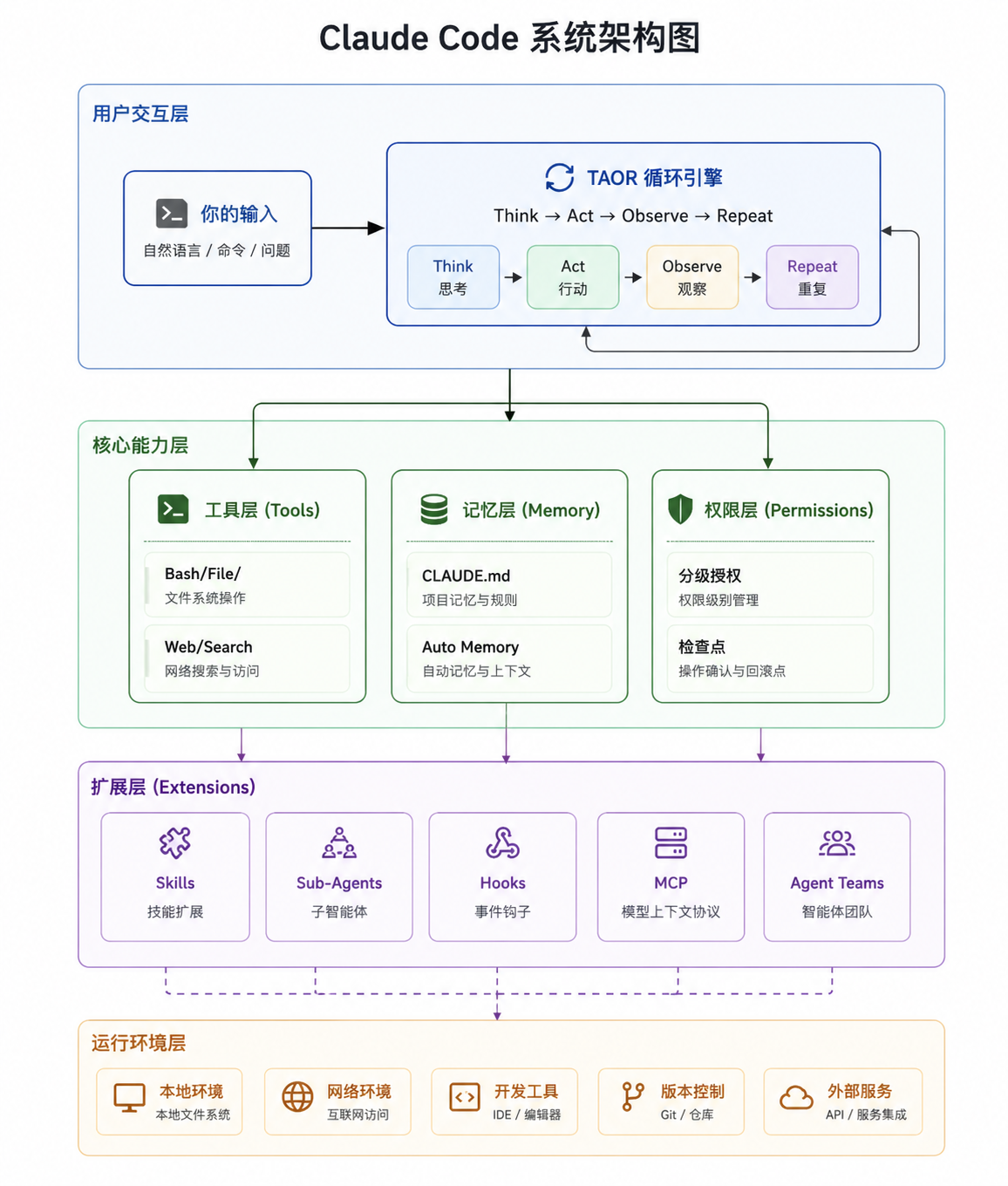
理解 Claude Code 的架构,有一个极好的比喻:大脑与躯体。
大脑(Brain)是 Claude 模型本身。它负责所有的认知工作——读懂你的意图,理解代码语义,规划解决步骤,判断当前行动是否合理,决定什么时候任务完成了。大脑是纯粹的推理机器,它本身不能做任何事,它只能"想"。
躯体(Harness)是 Claude Code 在你本地机器上运行的那套框架。它给大脑配备了感官和四肢:可以读写文件的手,可以执行命令的脚,可以搜索网络的眼睛,可以跨会话保存记忆的海马体。没有躯体,大脑只能原地空转;没有大脑,躯体不知道该做什么。
这个架构有一个非常重要的设计原则:运行时要尽量"愚蠢",智能全部留给模型。整个调度循环的代码大约只有 50 行逻辑。它不知道什么是 git,不知道什么是 npm,不知道代码是什么——它只知道:把工具交给模型,把模型的输出执行,把结果再喂给模型,循环往复。
这个设计的好处是双重的:首先,随着 Claude 模型本身的能力提升,整个系统的能力也随之提升,不需要重写任何框架代码;其次,系统的行为极易调试——如果出了问题,锅几乎总是在模型的提示词或上下文上,而不是隐藏在复杂的编排逻辑里。
有人曾经比喻说,之前的 AI 编码助手像是一个总需要人手把手教的实习生;而 Claude Code 更像是一个你只需要交代目标,他就能自己想办法完成的高级工程师。这个比喻的准确性,正是来自于 Harness 架构的设计哲学。
三、运转心脏:TAOR 循环,自主性的来源
如果你打开 Claude Code 的运行日志,你会看到一个不断重复的模式:Claude 先调用某个工具,工具返回结果,Claude 再调用下一个工具……这个看似简单的循环,是整个系统自主性的根基,叫做 TAOR 循环:Think(思考)→ Act(行动)→ Observe(观察)→ Repeat(重复)。
…