Claude Code 是如何工作的?一个自主编程智能体的架构深度解析
你有没有想过,当你在终端输入
claude "帮我重构这个认证模块"之后,接下来的几分钟里究竟发生了什么?Claude 是怎么在没有任何人逐步指导的情况下,自己找到文件、理解代码结构、做出修改、运行测试、再迭代修复的?这篇文章试图从架构层面,把这个过程讲清楚,面向对 AI 智能体设计有兴趣的工程师和产品人。如果你只是想用好 Claude Code,这篇文章同样能帮你建立一个清晰的心智模型,让你知道什么样的任务适合它,什么样的指令能让它发挥最大效果。
一、从聊天机器人到自主智能体:一次真正的范式跃迁
要理解 Claude Code 的架构,我们需要先理解它身处的历史节点。
2023 年之前,AI 应用基本上只有一种形态:你问,它答。ChatGPT 的出现让对话式 AI 飞入寻常百姓家,但本质上它是无状态的——每一轮对话都是独立的,AI 没有目标,没有计划,更没有行动能力。它像一个极其博学的图书管理员,你问什么,它查什么,查完就完了。
随后涌现出大量工作流编排工具,n8n、LangChain、Dify……这类工具的思路是:由工程师预先定义好 AI 应该执行的步骤——先调用这个 API,再走这个判断分支,然后输出到那里。模型被嵌入到一个硬编码的 DAG(有向无环图)里,充当某个节点上的智能处理单元。这是进步,但代价是严重的刚性:流程一旦设计好,AI 就被锁死在既定的轨道上,遇到意外情况毫无应对能力。
Claude Code 代表的是第三个阶段。在这里,控制权发生了根本性的翻转:不再是代码控制模型,而是模型控制代码。运行时框架变成了一个极度精简的"容器",所有的推理、规划、决策,全部交给 Claude 模型自己完成。它不只是在回答问题,而是在追求目标——理解你想要什么,制定策略,执行行动,观察结果,修正方向,直到任务完成。
这个转变听起来像是细节,实际上是量变引发质变的那个临界点。
二、核心架构:一个大脑,一副躯体
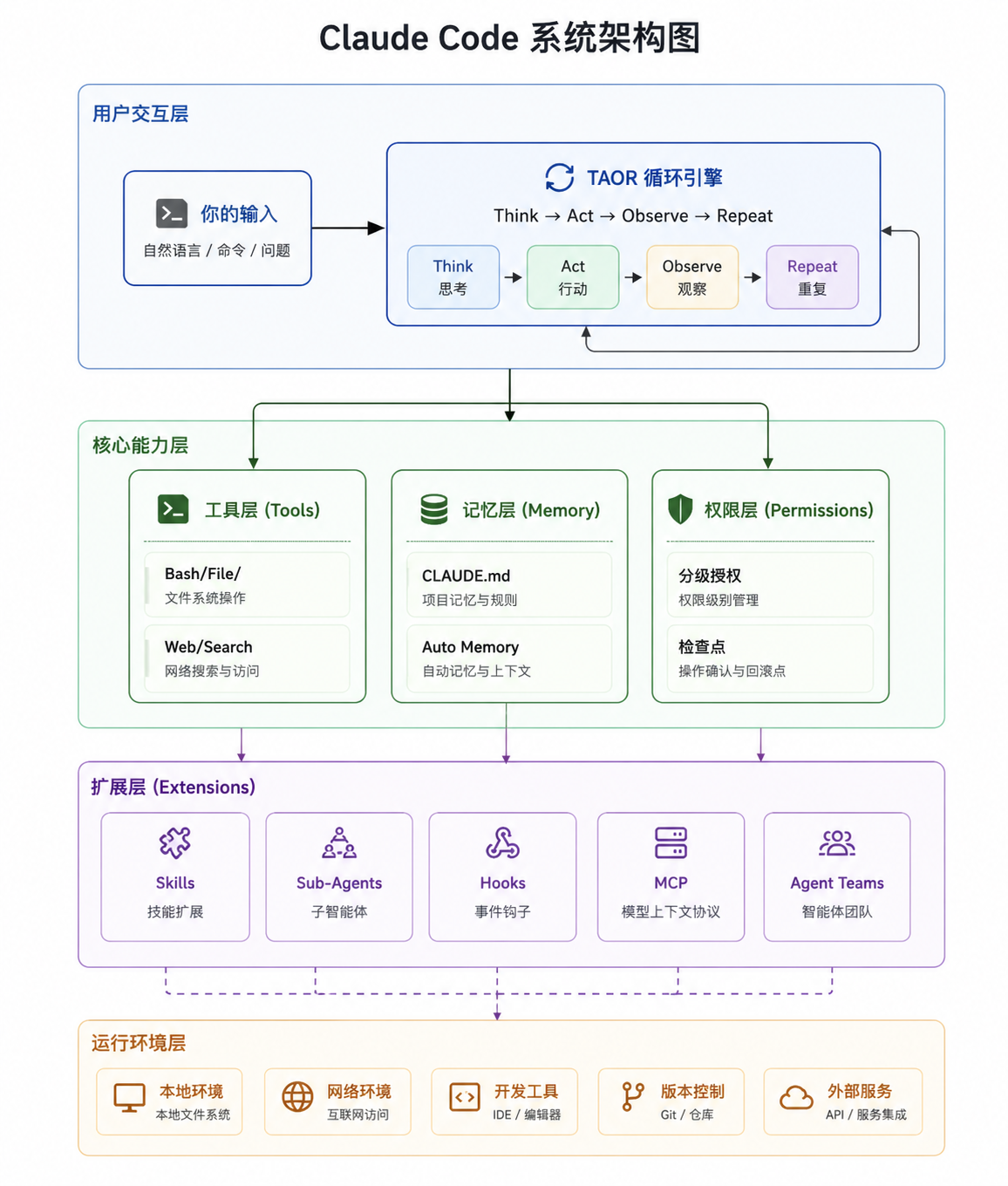
理解 Claude Code 的架构,有一个极好的比喻:大脑与躯体。
大脑(Brain)是 Claude 模型本身。它负责所有的认知工作——读懂你的意图,理解代码语义,规划解决步骤,判断当前行动是否合理,决定什么时候任务完成了。大脑是纯粹的推理机器,它本身不能做任何事,它只能"想"。
躯体(Harness)是 Claude Code 在你本地机器上运行的那套框架。它给大脑配备了感官和四肢:可以读写文件的手,可以执行命令的脚,可以搜索网络的眼睛,可以跨会话保存记忆的海马体。没有躯体,大脑只能原地空转;没有大脑,躯体不知道该做什么。
这个架构有一个非常重要的设计原则:运行时要尽量"愚蠢",智能全部留给模型。整个调度循环的代码大约只有 50 行逻辑。它不知道什么是 git,不知道什么是 npm,不知道代码是什么——它只知道:把工具交给模型,把模型的输出执行,把结果再喂给模型,循环往复。
这个设计的好处是双重的:首先,随着 Claude 模型本身的能力提升,整个系统的能力也随之提升,不需要重写任何框架代码;其次,系统的行为极易调试——如果出了问题,锅几乎总是在模型的提示词或上下文上,而不是隐藏在复杂的编排逻辑里。
有人曾经比喻说,之前的 AI 编码助手像是一个总需要人手把手教的实习生;而 Claude Code 更像是一个你只需要交代目标,他就能自己想办法完成的高级工程师。这个比喻的准确性,正是来自于 Harness 架构的设计哲学。
三、运转心脏:TAOR 循环,自主性的来源
如果你打开 Claude Code 的运行日志,你会看到一个不断重复的模式:Claude 先调用某个工具,工具返回结果,Claude 再调用下一个工具……这个看似简单的循环,是整个系统自主性的根基,叫做 TAOR 循环:Think(思考)→ Act(行动)→ Observe(观察)→ Repeat(重复)。
让我们用一个具体的故事来理解它。
假设你向 Claude Code 说了一句话:“我们的用户登录功能出了问题,帮我查一下。”
第一轮 Think:Claude 读取你的输入和当前的上下文(你的项目目录、CLAUDE.md 里的项目说明),开始思考:要查登录问题,首先需要找到相关的源代码在哪里。它决定使用搜索工具。
第一轮 Act:调用 grep 工具,搜索项目里含有 “login” 或 “auth” 关键词的文件。
第一轮 Observe:工具返回了五个匹配文件的路径。这些路径被追加到 Claude 的上下文中。
第二轮 Think:有了文件列表,Claude 决定先读取最核心的那个——src/auth/login.ts。
第二轮 Act:调用 Read 工具读取该文件内容。
第二轮 Observe:拿到了 200 行代码。Claude 在上下文中"看"到了这段代码,理解了它的结构,注意到了 session token 的处理逻辑里有一个可疑的过期时间计算……
这个循环不会停在这里。Claude 接下来可能会去读取测试文件,运行现有的单元测试,读取错误日志,最终定位到一个 token 刷新时没有正确更新过期时间的 bug。然后它开始修改代码,再跑一次测试,看到测试通过,这才判断任务完成,结束循环。
整个过程,你始终可以在旁边观察,也可以在任何时刻打断它,告诉它"不对,问题应该在会话这边,不是 token"。Claude 会立刻调整方向,重新规划。
这是传统工作流编排永远做不到的:没有哪个工程师能在任务开始之前,就把所有可能的分支路径全部预测到并写进 DAG。TAOR 循环的优雅之处,在于它把这种不确定性转化成了系统的核心能力——正因为不确定,所以每一步都需要重新思考,而这正是模型最擅长的事情。
还有一个细节值得一提:循环的终止条件也是模型自己判断的,而非硬编码的 if task == "done": break。Claude 会评估:测试通过了吗?需求是否满足了?有没有遗漏的边界情况?只有当它认为任务真正完成,循环才会结束。当然,系统也有 maxTurns 这样的硬性保护机制,防止模型陷入无限循环白白烧钱。
四、工具哲学:少即是多,Bash 就是万能适配器
谈到 AI 智能体,很多人的第一反应是:要给它更多工具。给它 Jira 工具,给它 GitHub 工具,给它数据库工具,给它 Slack 工具……结果往往是构建了一个臃肿的工具矩阵,每个工具都需要单独维护,文档需要更新,权限需要管理,版本需要升级。
Claude Code 走了一条截然相反的路:极简工具集 + 一个 Shell,就能完成几乎所有事情。
官方定义了五大类工具,涵盖了一个工程师日常工作的所有核心能力:
- 文件操作:读取、创建、编辑、重命名——这是代码的物质载体
- 搜索:按文件名模式查找,用正则搜索内容——这是在代码森林里导航
- 执行:运行任意 Shell 命令,包括启动服务、运行测试、调用 git——这是真正的行动
- Web:搜索网络、获取文档页面——这让 Claude 可以查阅自己不知道的知识
- 代码智能:查看类型错误、跳转定义、查找引用——这需要配合 IDE 插件使用
这五类工具看起来不多,但隐藏着一个极其强大的设计:Bash 工具是万能适配器。
当 Claude 有了执行 Shell 命令的能力,它实际上获得了访问整个命令行生态的入口。你不需要为 git 写一个 git 工具,因为 git commit -m "fix auth bug" 直接在 Bash 里就能跑。你不需要为 Docker 写一个容器工具,因为 docker build . 本来就是一条命令。你不需要为 npm 写一个包管理工具,因为 npm test 就是 Bash。
更妙的是,这些工具可以任意组合——就像人类工程师在终端里写管道命令一样:
git diff HEAD~1 | grep "^+" | grep -v "^+++" | wc -l
这一行命令告诉你这次提交新增了多少行代码。Claude 完全可以自行构建这样的命令组合,而不需要有人专门为它提供一个"统计代码变更量"的工具。
这就是 Claude Code 的工具哲学:与其构建一百个脆弱的专用集成,不如给模型一个 Shell,然后相信它有足够的工程直觉去组合出任何它需要的工作流。
五、分层记忆系统:让 AI 永远不从零开始
这里我们来聊一个很多人没有深想过的问题:Claude Code 是怎么记住你的项目的?
大语言模型本身没有持久化记忆。每次调用 API,都是一次全新的开始。如果你不把项目背景告诉它,它就只是个聪明的陌生人,对你的代码库一无所知。
早期的 AI 编程助手大多是这样工作的:每次你都需要粘贴上下文,告诉它"我们用的是 TypeScript,代码规范是这样的,这个模块的主要逻辑在这里"。时间一长,这种重复变成了一种负担,而且你粘贴的上下文越来越难以完整覆盖项目的全部知识。
Claude Code 用一套六层分级记忆架构来系统性地解决这个问题。想象它是一栋六层楼,越高层的规则约束越广泛,越底层的规则越具体、越个人化:
第一层:组织策略(Managed Policy) 这一层由你的公司或团队的管理员配置,强制应用于所有成员。典型内容是:不允许提交未经安全审计的代码、所有外部 API 调用必须经过审批。这一层保证了团队基线的一致性。
第二层:项目指令(CLAUDE.md)
这是最核心、最常用的一层。CLAUDE.md 是一个你手动维护的 Markdown 文件,放在项目根目录下。你可以在里面写任何你希望 Claude 每次工作时都知道的事情:这个项目是用 Next.js 14 构建的,数据库用的是 PostgreSQL,运行测试用 pnpm test,提交代码前必须先跑 lint,核心业务逻辑在 src/core/ 目录……
每次 Claude Code 启动时,它会自动找到并读取 CLAUDE.md,把这些背景知识注入到自己的上下文里。从这一刻起,Claude 就不再是陌生人,而是一个了解你项目的协作者。
第三、四层:本地规则与用户配置 这两层处理的是个人偏好和跨项目的设置。比如你个人习惯让 Claude 在回复时使用中文,或者你有一些所有项目通用的代码风格要求。这些配置不会影响其他团队成员,只作用于你自己的工作环境。
第五层:自动记忆(Auto Memory)
这一层是最有趣的,也是最体现系统"自学习"特性的。在你和 Claude 的工作过程中,Claude 会自动识别那些值得被记住的规律——你喜欢怎样的注释风格,项目里有哪些特殊的编码约定,你倾向于用什么样的变量命名模式。这些发现会被写入 MEMORY.md 文件,在未来的每次会话开始时自动加载(最多前 200 行或 25KB)。
这意味着,你和 Claude Code 合作的时间越长,它就越了解你,就像一个共事多年的同事,不需要你每次重新解释偏好,也不需要你事先写出所有规则——它从实践中学。
第六层:会话临时上下文 这是当前这次对话中发生的一切——你说的话,工具返回的结果,Claude 做出的决策。这一层是最动态的,每次新会话都从空白开始,但上面几层的记忆让这个"空白"不是真正的空白,而是在一个已经有背景知识的基础上起步。
这六层的设计逻辑是:让 AI 永远不从零开始,但又永远保持上下文的精简。不是把所有历史都堆进去,而是把值得记住的精华提炼出来,在正确的时机注入正确的位置。
六、上下文管理:在一个有限的窗口里,安排无限的工作
如果说记忆系统解决的是"Claude 知道什么"的问题,那么上下文管理解决的是"Claude 能同时处理多少信息"的问题。
Claude 的上下文窗口很大,但它终究是有限的。随着一次任务的推进,上下文里会不断积累:你说的话、Claude 的回复、每次工具调用的输入和输出、读取的文件内容、运行命令的输出……当你在重构一个复杂模块时,这些内容可能轻松就把上下文填满。而一旦上下文满溢,就会发生所谓的"上下文崩溃"(Context Collapse)——Claude 开始忘记任务开头说了什么,开始产生幻觉,开始重复已经做过的工作。
这不是假想中的风险,而是几乎每个重度使用 AI 智能体的工程师都遇到过的噩梦。
Claude Code 为此构建了一套多层次的上下文管理策略。
自动压缩:优雅地遗忘
第一道防线是自动压缩(Auto-Compaction)。当上下文使用量接近上限时,系统会自动介入:先清理较旧的工具调用输出(这些往往是最占空间的),然后如果空间仍然不够,就会对对话历史进行 AI 摘要——把早期的几十轮对话压缩成一段核心决策的总结,腾出空间继续工作。
这里有一个值得注意的细节:自动压缩会丢失细节,但不应该丢失方向。对话早期你说"不要修改 UserModel,那里有个临时 hack"这样的约束,有可能在压缩中消失。这就是为什么官方建议把重要的、持久性的规则写进 CLAUDE.md,而不是在对话里临时说——写进文件的规则每次都会重新加载,而对话里说的话迟早会被压缩掉。
你也可以手动控制压缩的边界:
/compact focus on the API changes
这告诉 Claude 在压缩时重点保留 API 变更相关的信息,其余的可以大胆简化。
子智能体隔离:让繁重的工作在别处完成
第二道防线更为根本:子智能体(Sub-Agents)。
当你需要 Claude 做一件"探索性"的工作——比如"帮我理解整个认证模块的设计逻辑"——这件工作需要读取大量文件,可能涉及几十个工具调用,会产生大量的中间上下文。如果全部在主会话里做,主上下文很快就会被这些探索工作填满,等到你真正需要它开始写代码的时候,已经没有空间了。
子智能体的解法是:把这件探索工作分叉出去,在一个完全独立的上下文窗口里执行。子智能体有自己的 TAOR 循环,有自己的工具调用历史,有自己的上下文管理。当它完成任务时,它只把一份精炼的摘要返回给主智能体——“认证模块主要由三个组件构成,核心逻辑在 X 文件,依赖了 Y 和 Z”。
主智能体的上下文,只消耗了这一小段摘要,而不是探索过程中读取的全部文件。子智能体的上下文窗口在任务完成后直接丢弃。
主智能体 子智能体(独立上下文)
───────── ──────────────────────
"探索认证模块" ──────▶ 读取 20 个文件
运行 15 次工具调用
整理分析结果
◀─── 摘要 ──── "核心结构是这样的..."
上下文消耗:一段摘要 上下文消耗:用完即弃
这种设计让主智能体可以保持"轻装上阵",把宝贵的上下文空间留给真正需要深度推理的工作。
Skills 与 MCP 的按需加载:工具描述 vs. 工具内容
第三道防线涉及到 Claude Code 的两个核心扩展机制:**Skills(技能)**和 MCP(Model Context Protocol)。
先说 Skills。技能是你为 Claude 定义的可复用指令集。比如你有一套代码审查的规范,或者部署到生产环境的标准操作流程,你可以把这些写成一个 Skill 文件,之后在需要的时候用 /review 或 /deploy 命令调用。
天真的实现方式是:把所有 Skill 的全部内容在会话开始时一次性加载进上下文。如果你定义了 20 个技能,每个技能有 500 个 token 的详细说明,那每次会话一开始就要消耗 10,000 个 token,即便你这次完全用不到其中 18 个。
Claude Code 的做法是:只加载描述,不加载内容。会话开始时,每个 Skill 只有一段简短的描述(“这个技能用于执行代码审查,适合在代码变更后使用”)被放入上下文。当 Claude 判断当前任务需要某个技能时,才把那个技能的完整指令内容按需注入。对于你手动调用的技能(通过斜杠命令),可以设置 disable-model-invocation: true,让描述连都不进上下文,彻底按需加载。
MCP 的情况更加极端。一个配置完善的 Claude Code 环境可能连接了数十个甚至上百个外部服务的 MCP 工具。如果把所有工具的定义(包括参数说明、使用示例)全部塞进上下文,光是工具定义本身可能就消耗掉几万个 token。
Claude Code 的解法是语义工具搜索:工具名称在会话开始时加载,但完整的工具定义只在 Claude 决定要使用某个工具时,通过语义搜索找到并按需注入。对 Claude 而言,这就像有一本目录——它知道有哪些工具存在,但工具的详细用法手册只在翻到那一页时才展开。
这三道防线共同构成了 Claude Code 的上下文管理策略:自动压缩解决了历史膨胀,子智能体解决了任务膨胀,按需加载解决了工具膨胀。三者缺一不可,共同保证系统在长时间、大规模任务中的稳定运行。
七、权限体系:给 AI 一把有刻度的钥匙
有了 Shell 访问权,Claude Code 可以做任何事——包括你不想让它做的事。这不是在危言耸听;一个配置不当的 AI 智能体,完全可能因为理解偏差而删除了错误的文件,或者把敏感信息 push 到了公开仓库。
这就是为什么权限体系是 Claude Code 架构中不可缺少的一环。
Claude Code 设计了一套精细的分层权限模型,从最谨慎到最开放,共分五档:
最保守的是 Plan 模式。在这个模式下,Claude 只能使用只读工具——读文件,搜索内容,理解代码——但不能做任何修改,不能运行任何命令。它会给你一份详细的行动计划,告诉你它打算做什么,等你确认后再切换到其他模式实际执行。这个模式非常适合在陌生的代码库里"踩点",或者在执行高风险操作前先预演一遍。
Default 模式是日常工作中最常用的。每次 Claude 想要修改文件或执行 Shell 命令,它都会先停下来问你:“我打算这样做,可以吗?“这保证了你始终在循环里,没有任何动作会在你不知情的情况下发生。代价是频繁的确认提示,会打断工作节奏。
acceptEdits 模式做了一个精细的权衡:文件编辑不再需要确认,但 Shell 命令仍然需要。这个模式背后的逻辑是:文件修改是相对低风险、可回滚的操作;而 Shell 命令可能触发网络请求、数据库写入、外部服务调用等副作用,需要更多谨慎。对于需要频繁修改代码但不想被反复打断的场景,这是个合理的折衷。
dontAsk 模式会自动批准所有在白名单里的操作。你可以在 .claude/settings.json 里配置:“我允许 Claude 自动运行 npm test、git status、git diff,但对于 git push、rm -rf 这类操作,还是要问我”。这给了你精细粒度的控制:信任安全的操作,对高风险操作保持警觉。
最开放的是 bypassPermissions 模式,跳过所有检查。这一般只在企业托管的隔离环境中使用,或者在 CI/CD 流水线里——因为那里已经有了其他层次的安全保障。
Shift+Tab 可以在这些模式之间快速切换。你还可以在对话里直接告诉 Claude"之后所有的 git 操作都不用问我了”,它会记住这个会话级别的权限设置。
值得反思的是:权限设计本质上是一个关于信任的问题。你愿意信任这个 AI 同事做到什么程度?这个问题没有标准答案——取决于任务的风险级别、你对模型判断的了解程度、以及当前工作环境的安全要求。Claude Code 的权限体系做的事情,是把这个本来很模糊的信任问题,转化成一套可操作、可配置、可随时调整的具体设置。
八、扩展生态:用声明,而非编程,来构建能力
说到这里,Claude Code 的核心架构已经基本清晰了。但还有一个维度非常值得深入探讨,那就是它的扩展性。
大多数工具的扩展性意味着:你要写代码。写一个插件,写一个 API 客户端,写一个自定义 Action。这对工程师来说尚可接受,但对整个团队来说,门槛就高了。
Claude Code 的扩展生态几乎完全是声明式的:你只需要写文本文件——Markdown 和 JSON,不需要写任何代码——就能大幅扩展它的能力边界。这个设计决策的影响远比表面看起来的大。
Skills:把工作流变成一句话
Skills 就像是 Claude Code 的"宏命令”,但比宏命令智能得多。
一个典型的使用场景:你的团队有一套标准的代码审查流程——先检查变更的影响范围,再看测试覆盖率,再审查 API 设计,最后给出优先级分级的反馈。这套流程可以被写成一个 Skill:
---
name: code-reviewer
description: 执行标准代码审查。在代码发生变更后主动使用。
tools: Read, Glob, Grep, Bash
disallowedTools: Write, Edit
model: sonnet
---
你是一位资深代码审查员。当被调用时:
1. 运行 git diff 查看最近的变更
2. 分析变更的影响范围
3. 检查测试覆盖率
4. 审查 API 设计的合理性
5. 按优先级输出反馈:Critical → Warning → Suggestion
之后,任何团队成员在做完改动后只需说一句 /review,Claude 就会按照这套标准流程执行完整的代码审查。流程的知识被编码进了一个文件,而不是依赖于某个人的记忆或口口相传的惯例。
Sub-Agents:给 AI 配备专业的助手团队
如果 Skills 是"宏命令",那么自定义子智能体就是"专用助手"。
你可以为不同的工作场景配置专门的子智能体,每个都有自己的工具权限、使用的模型版本、记忆范围,甚至是特定的工作风格。比如:
- 一个只有读权限的"探索型"子智能体,专门用于理解陌生代码库,不会意外修改任何东西
- 一个配置了
model: opus的"架构决策"子智能体,在面对复杂的设计权衡时调用,用更强的推理能力来分析 - 一个专注于测试的子智能体,持续监控测试覆盖率,在覆盖率下降时主动提醒
子智能体可以有自己的记忆(memory: user 配置让它把学到的模式持久化),可以预加载特定的 Skills,可以限制或扩展可用的工具集。它们彼此可以链式调用:先用"探索"智能体理解代码,再把结果交给"实现"智能体去写代码,最后由"审查"智能体检查质量。
MCP:连接整个数字世界
MCP(Model Context Protocol)是 Claude Code 对外连接能力的核心协议。它的野心很简单:成为 AI 智能体连接外部服务的通用标准,就像 USB 是硬件接口的通用标准一样。
有了 MCP,你可以让 Claude Code 直接读取你的 Jira 工单,而不需要在对话里粘贴工单内容;可以让它查询你的 PostgreSQL 数据库,验证代码修改的实际影响;可以让它访问 Figma 设计文件,确保实现和设计一致;甚至可以让它控制本地运行的浏览器,进行端到端的功能验证。
MCP 支持三种传输模式,分别适用于不同的集成场景:本地工具(通过 stdio),远程服务(通过 HTTP),以及需要实时推送更新的场景(通过 SSE)。配置完成后,这些外部能力对 Claude 来说就和内置工具无异——只是另一组它可以使用的"感官和四肢"。
结合前文提到的语义工具搜索,即便你连接了 100 个 MCP 工具,也不会在上下文里产生可见的性能损耗。Claude 只在真正需要某个工具时,才去查阅它的详细说明。
Hooks:让规则成为系统的一部分
最后一个扩展机制是 Hooks(钩子),它解决的是一类特殊问题:有些规则太重要了,不能依赖 AI 去记住和执行,必须通过确定性的代码来强制保证。
Hooks 在 Claude 的工作循环的各个生命周期节点上挂载——PreToolUse(工具调用前)、PostToolUse(工具调用后)、SessionStart(会话开始时)、SessionEnd(会话结束时)等。这些钩子是普通的脚本,完全在 LLM 循环之外运行,不经过任何 AI 推理,保证了百分之百的确定性。
一个极其实用的例子:配置 PostToolUse 钩子,每次 Claude 写入文件后自动运行 ESLint,并把 lint 结果返回给 Claude。这样不管 Claude 写出什么样的代码,都会自动经过一道代码规范检查,而且修复建议会直接进入 Claude 的上下文,让它自行改正。你不需要告诉 Claude “记得遵守 lint 规范”——规范变成了一个自动运行的外部检查,而不是一条需要被"记住"的指令。
九、会话管理:把 AI 的工作历史当成代码版本来管理
Claude Code 有一个设计细节,第一次接触时可能会让人觉得"这有必要吗",但用过之后就会觉得"少了这个简直没法用"——那就是它的会话持久化和分叉机制。
每次和 Claude Code 的对话,都会被实时记录到本地的一个 JSONL 文件里(存放在 ~/.claude/projects/ 目录下)。这个记录包括你说的每一句话、Claude 的每一个回复、每次工具调用的输入和输出、每个文件读取的内容。这个记录本身对你是透明的——它就是一个文本文件,你随时可以打开查看。
这种持久化带来了三个关键能力:
恢复(Resume):如果你在任务执行一半时需要去开个会,或者电脑突然关机,下次重新打开终端,运行 claude --continue,Claude 会完整恢复到上次中断的状态——不只是知道你们讨论了什么,而是拥有完整的工具调用历史和决策上下文,可以从中断处继续推进。
分叉(Fork):这是一个更有趣的功能。假设 Claude 已经完成了一个功能的基础实现,现在你想探索两种不同的重构方向,不确定哪个更好。使用 claude --continue --fork-session 可以基于当前状态创建一个分支会话——原来的对话历史被复制一份,新会话从这个节点继续,但两个会话互不干扰。你可以在分支会话里大胆探索,如果发现方向不对,原会话完好无损,随时可以回去。
这和 git 的分支机制几乎是同样的思维模型:探索性的工作不应该污染稳定的主线,两条路可以并行探索,最终选择更好的那条合并进来。
检查点与回滚:在文件层面,Claude Code 在每次修改文件之前都会自动创建快照。如果 Claude 的修改破坏了某些东西,按 Esc 两次可以回到上一个安全状态,就像 git checkout 一样,但不需要你手动管理。检查点是局部的、自动的,完全在 git 之外工作——这很重要,因为有些中间状态你不想污染 git 历史,但又需要能够回滚。
十、架构的自我进化哲学:Harness 应该越来越薄
最后,我想聊一个超越技术细节的设计哲学,因为它揭示了 Anthropic 对 AI 智能体未来的一种判断。
在社区的逆向分析中,有人发现了一个有趣的现象:Claude Code 的 Harness 代码,随着新版本的发布,并没有变得更复杂,某些地方反而在变简单。一些之前需要硬编码的步骤——比如"在开始任务前先制定计划"这样的规划逻辑——在新版本里被删掉了,因为最新的 Claude 模型已经足够聪明,能在没有外部强制的情况下自然地进行规划。
这背后是一个深刻的架构原则:Harness 的职责,是弥补当前模型能力的不足,而不是永久代替模型的判断。当模型变强,Harness 就应该缩减。一个好的智能体架构,随着时间推移应该越来越简单,因为越来越多的"脚手架"代码可以被模型自身的能力吸收。
这与许多其他 AI 编排框架的发展路径截然相反。那些框架往往越来越复杂——每当发现一个新的 AI 缺陷,就加一个补丁;每当需要一个新功能,就加一层封装。最终变成一个没有人完全理解的庞然大物,脆弱,难以维护,也难以随模型升级而进化。
Anthropic 的赌注是:未来的模型足够强大,今天大多数 Harness 里的"脚手架"都会变得多余。因此,从一开始就保持 Harness 的精简,是为未来的进化留好空间,而不是积累技术债务。
尾声:一个思维模型,而非一份功能清单
读完这篇文章,我希望你带走的不是一份 Claude Code 功能的清单,而是一个思维模型:
Claude Code 是一个自主的工程师同事,而不是一个聪明的命令执行器。
这个区别影响了你应该怎么和它协作。你不应该像给计算机下指令一样告诉它每一个步骤,而应该像和一个同事沟通一样告诉它目标和约束,然后给它空间去找到自己的路径。你应该维护好 CLAUDE.md,就像你会在项目里写 README 一样,因为这是你和这个同事建立共同语言的地方。你应该善用 Sub-Agents,把探索性的工作和执行性的工作分开,就像你在大型项目里会分配不同的人负责不同的工作模块。
最重要的是:理解它是如何工作的,才能知道什么时候信任它,什么时候介入,什么时候对它说"不对,重新想想"。
就像任何真正有用的工具一样,掌握它的内在逻辑,才能真正发挥它的价值。